一个由来自谷歌、苏黎世联邦理工学院、NVIDIA和RobustIntelligence的计算机科学研究人员组成的团队重点介绍了两种数据集投毒攻击,不良行为者可能会利用这些攻击来破坏AI系统结果。该小组撰写了一篇论文,概述了他们已识别的攻击类型,并将其发布在arXiv预印本服务器上。
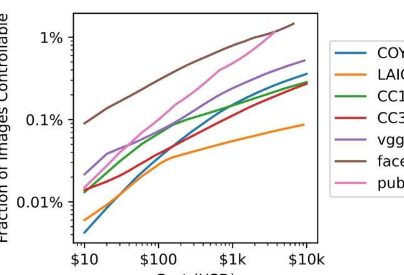
随着深度学习神经网络的发展,人工智能应用已经成为大新闻。由于它们独特的学习能力,它们可以应用于各种环境。但是,正如这项新工作的研究人员指出的那样,他们的共同点是需要高质量的数据用于培训目的。
因为这样的系统从他们看到的东西中学习,所以如果他们遇到错误的事情,他们无法知道,因此将其纳入他们的规则集。例如,考虑一个AI系统,该系统经过训练可以将乳房X光照片上的模式识别为癌性肿瘤。这样的系统将通过向它们展示许多在乳房X光检查中收集的真实肿瘤的例子来训练。
但是,如果有人将显示癌性肿瘤的图像插入到数据集中,但它们被标记为非癌性,会发生什么情况?很快系统就会开始遗漏这些肿瘤,因为它被教导将它们视为非癌性的。在这项新的努力中,研究团队表明,使用互联网上公开可用的数据训练的人工智能系统也会发生类似的事情。
研究人员首先指出,互联网上的URL所有权通常会过期——包括那些已被AI系统用作来源的URL。这使得它们可供想要破坏AI系统的邪恶类型购买。如果购买了此类URL,然后将其用于创建包含虚假信息的网站,人工智能系统会将这些信息添加到其知识库中,就像添加真实信息一样容易——这将导致人工智能系统产生不太理想的结果。
研究小组将这种类型的攻击称为分裂视图中毒。测试表明,这种方法可用于购买足够的URL来毒化大部分主流AI系统,只需10,000美元。
还有另一种方法可以颠覆人工智能系统——通过操纵维基百科等众所周知的数据存储库中的数据。研究人员指出,这可以通过在定期数据转储之前修改数据来实现,从而防止监视器在数据发送到人工智能系统并被其使用之前发现这些变化。他们称这种方法为抢先投毒。
更多信息:NicholasCarlini等人,PoisoningWeb-ScaleTrainingDatasetsisPractical,arXi