《智能计算》上发表的一篇新论文提出了复杂动态环境中智能决策的强化学习面临的主要挑战。强化学习是机器学习的一种,其中代理通过与环境交互来学习做出决策并获得奖励或惩罚。
代理的目标是通过确定在不同情况下采取的最佳行动来最大化长期奖励。然而,南京大学的吴晨阳和张宗章研究员坚信,单纯依靠奖惩的强化学习方法无法成功产生学习、感知、社交、语言、泛化和模仿等智能能力。
吴和张在他们的论文中指出了他们认为当前强化学习方法的缺点。一个主要问题是需要通过反复试验收集的信息量。
与人类可以利用过去的经验进行推理并做出更好的选择不同,当前的强化学习方法严重依赖于大规模重复尝试的代理来学习如何执行任务。当处理涉及影响结果的许多不同因素的问题时,智能体有必要尝试大量的示例来找出最佳方法。
如果问题的复杂性略有增加,则所需示例的数量会快速增长,从而使代理高效运行变得不切实际。更糟糕的是,即使代理拥有确定最佳策略所需的所有信息,弄清楚它仍然非常困难且耗时。这使得学习过程缓慢且低效。
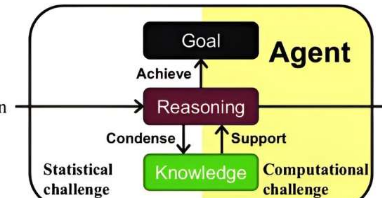
统计效率低下和计算效率低下都阻碍了从头开始实现通用强化学习的实用性。当前的方法缺乏在没有大量计算资源的情况下充分发挥强化学习在开发多种能力方面的潜力所需的效率。
吴和张认为,可以通过获取观测中的高价值信息来克服统计和计算挑战。这些信息可以仅通过观察来改进策略,而不需要直接交互。想象一下,一个智能体通过下围棋(换句话说,通过反复试验)来学习下围棋需要多长时间。
然后想象一下,通过阅读Go手册(换句话说,通过使用高价值信息),智能体可以学习得快得多。显然,从信息丰富的观察中学习的能力对于有效解决复杂的现实世界任务至关重要。
高价值信息具有两个独特的特征。首先,它不是独立且同分布的,这意味着它涉及复杂的相互作用和依赖关系,这与过去的观察不同。要充分理解高价值信息,必须考虑其与过去信息的关系并承认其历史背景。
高价值信息的第二个特征是它与计算感知代理的相关性。拥有无限计算资源的智能体可能会忽视高级策略,而仅依赖基本级规则来得出最佳方法。这些代理忽略更高级别的抽象,这可能会导致不准确,并且优先考虑计算效率而不是准确性。
只有意识到计算权衡并能够欣赏计算有益信息的价值的代理才能有效地利用高价值信息的好处。
为了使强化学习能够有效利用高价值信息,必须以新的方式设计代理。根据他们将智能决策形式化为“有界最优终身强化学习”,吴和张确定了代理设计中的三个基本问题:
克服信息流的非独立性和同分布性,动态获取知识。这需要将过去与未来联系起来,并将持续的信息流转化为可供未来使用的有用知识。
然而,有限的计算资源使得不可能记住和处理整个交互历史。因此,需要结构化知识表示和在线学习算法来增量组织信息并克服这些限制。
在给定有限资源的情况下支持有效推理。首先,在计算限制下,有助于理解、预测、评估和行动的普遍知识已经不够了。为了应对这一挑战,高效推理需要一种结构化的知识表示,该知识表示能够利用问题结构并帮助代理以特定于问题的方式进行推理,这对于计算效率至关重要。
推理过程的第二个方面是顺序决策。这在指导智能体确定其行动、处理信息和制定有效的学习策略方面发挥着关键作用。因此,为了最大化计算资源的利用率,元级推理变得必要。第三,成功的推理需要智能体有效地将其内部能力与从外部观察中收集的信息结合起来。
确定推理目标,确保代理人寻求长期回报,避免仅仅受短期利益驱动。这就是所谓的探索-利用困境。它涉及在探索环境以收集新知识和根据现有信息利用最佳策略之间找到平衡。
当考虑计算角度时,这种困境变得更加复杂,因为代理的资源有限,必须在探索替代计算方式和利用现有最佳方法之间取得平衡。由于在复杂环境中探索一切是不切实际的,因此智能体依靠其现有知识来概括未知的情况。解决这一困境需要将推理目标与智能体的长期利益结合起来。还有很多东西需要理解,特别是从计算的角度来看。